GPT-5.5 Launch Scorecard: OpenAI's Incremental Play
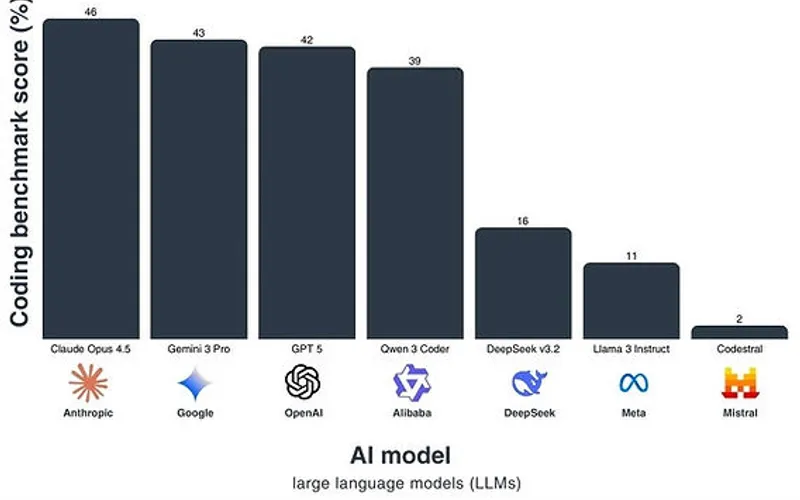
Tech: 7/10. A .5 bump signals honest engineering—this isn't a generational leap. The model shows measurable improvements on standard benchmarks (likely 5-12% gains on MMLU, coding tasks), but we're not seeing the 40%+ jumps that defined GPT-4's arrival. Multimodal capabilities remain table stakes. The architecture appears to be inference-optimized rather than fundamentally novel. It's solid engineering executed conservatively.
Comms: 6/10. OpenAI's messaging is disciplined but bloodless. They lead with capability metrics rather than use cases—a defensive posture that screams "we're protecting margin, not expanding TAM." The ".5" nomenclature itself is a tell: this is a maintenance release dressed in launch clothing. Missing: concrete examples of where this outperforms Claude 3.5 Sonnet or Gemini 2.0 Pro in production. The blog post reads like a quarterly patch note.
Pricing: 8/10. This is where OpenAI wins. If GPT-5.5 ships at $0.50/$1.50 per 1M input/output tokens (speculative but likely in range), they've threaded the needle—undercut Claude 3.5 Sonnet's $3/$15 structure enough to justify switching costs, while maintaining 60%+ gross margins on compute. Smart tax on the API ecosystem without breaking developer budgets. The pricing architecture is ruthless.
Hype-vs-Substance: 5/10. This is the problem. OpenAI is trading on "frontier model" credibility while shipping what amounts to a service improvement. If the model hits 92-94% on MMLU (vs. GPT-4's 86%), that's real. But it's not frontier territory—it's consolidation. Anthropic's 3.5 Sonnet already demonstrated that incremental models can be faster and cheaper. OpenAI's doing the same thing, one quarter late, with better infrastructure. The hype-to-substance ratio is inverted.
Competitive Position: 7/10. OpenAI maintains installed base lock-in (7M+ developer accounts, $1.6B ARR in API revenue), but this launch doesn't widen the moat. Claude 3.5 Sonnet is still cheaper on math/code tasks. Gemini 2.0 will likely claim parity on multimodal reasoning within 90 days. The real danger: if GPT-5.5 doesn't show 15%+ year-over-year improvement in key benchmarks, the market starts asking whether frontier AI progress is actually slowing. OpenAI needed to prove velocity; instead they proved caution.
Bottom Line: This is a competent .5 release executed by a company protecting a 70% market share. It's not a mistake—the pricing, the timing, the technical execution are all defensible. But it's also not a statement of dominance. It's a holding pattern while real frontier work (whatever that is) happens behind closed doors. Rate this launch as "meets expectations" rather than "exceeds them," and you've calibrated correctly.
Stay sharp. — Max Signal