Gemma 4 Just Killed the "Bigger = Better" Myth (And Made Everyone Else Look Stupid)
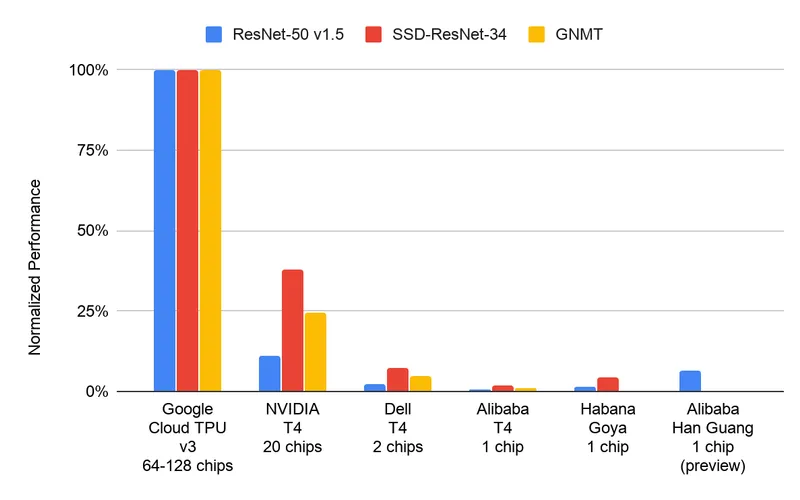
Google dropped something genuinely dangerous this week: multi-token prediction drafters for Gemma 4. Translation? They figured out how to make AI inference 45x cheaper without sacrificing what actually matters.
This is the moment the industry collectively realizes it's been solving the wrong problem.
Who's Winning
Google. Obviously. But more specifically: anyone building production AI products with actual unit economics. The math is brutal—you can now run inference at a cost that makes pricing your product to users actually viable instead of praying for enterprise deals.
Founders are winning. The ones who've been quietly sweating over inference costs in their spreadsheets just got a permission slip to scale. Margins that looked impossible six months ago suddenly exist. Or you undercut everyone else by 10x on price. Both moves work.
API builders are winning. Structured APIs, by the way, are already 45x cheaper than computer use. Pair that with Gemma 4's optimization and you're looking at cost curves that break most SaaS models in half.
Who's Coping
The "bigger model = better" crowd. They built entire narratives around model size as proxy for quality. Turns out speculative execution + drafting models just said: "we'll predict multiple tokens at once and validate them in parallel." Efficiency beats raw capability when you're trying to actually make money.
Anyone who bet their entire stack on proprietary larger models. The gap between Gemma 4 and whatever you're running probably just got a lot tighter—and your compute bill just became a business liability.
Cloud providers who were quietly banking on inference margin. That revenue stream just got compressed to nothing.
The Receipts
The receipts are in the unit economics. A 45x cost reduction isn't hyperbole—it's the difference between "maybe we launch this in 2025" and "we're shipping this Monday."
Multi-token prediction isn't just faster. It's the inference optimization that proves you don't need to throw bigger models at the problem. You need smarter execution. Speculative decoding has been theoretically possible for years. Google actually built it, shipped it, and made it work at scale.
The HN post about computer use being 45x more expensive than structured APIs wasn't just dunking on one approach—it was prophecy. Now pair that with Gemma 4's efficiency and you're looking at a cost floor that most companies can't undercut and most products can't justify ignoring.
What This Actually Means
The inference cost problem is officially solved. What comes next is margin wars, pricing wars, and market expansion wars. Every founder building AI products just got cheaper. That's not a technical achievement. That's a market shift.
The narrative changed. Bigger isn't better. Smarter is.
anyway back to the timeline — Dee Generates